Utilizzo la funzione in oggetto, e la sua controparte, per criptare le password degli utenti della mia applicazione. In alcuni casi mi vedo negato l'accesso.
Indagando uno di questi casi, trovo una differenza tra il valore che mi mostra il db (oracle 10) e quello che invece vedo nel debug di InDe (allegato).
Cosa può essere? Caratteri non supportati dal charset di oracle? Come posso risolvere?
Visto che ci sono, un ulteriore domanda:
Se il campo nel db è di 20 caratteri e la password inserita dall'utente è di 20 caratteri, corro il rischio che il risultato della SimpleCrypter superi la lunghezza del campo nel db?
It is currently 7 June 2025, 5:36 Advanced search
SimpleCrypter
7 posts
• Page 1 of 1
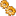 SimpleCrypter
SimpleCrypter
![]() by r.bianco » 16 April 2013, 8:23
by r.bianco » 16 April 2013, 8:23
- Attachments
-
- Immagine.png (7.01 KiB) Viewed 10676 times
only work and no play makes jack a dull boy
- r.bianco
- Posts: 4979
- Joined: 8 November 2010, 16:46
Re: SimpleCrypter
![]() by g.cassanelli » 16 April 2013, 9:15
by g.cassanelli » 16 April 2013, 9:15
Per i caratteri non supportati non saprei.
Per la lunghezza invece abbonda, perchè criptando la lunghezza della stringa si allunga non poco.
Per la lunghezza invece abbonda, perchè criptando la lunghezza della stringa si allunga non poco.
Informatica ! Meglio lavorare con il granito, è duro, ma è stabile ! - Computer Science ! Better to work with granite, it's hard, but it's stable !
Giuseppe Cassanelli http://www.lab-ud.com
Giuseppe Cassanelli http://www.lab-ud.com
-

g.cassanelli - Posts: 2653
- Joined: 9 November 2010, 19:00
- Location: BOLOGNA
Re: SimpleCrypter
![]() by lucabaldini » 16 April 2013, 9:28
by lucabaldini » 16 April 2013, 9:28
Per i caratteri direi che potrebbe dipendere da Oracle.
Controlla se il tuo DB è unicode (il set di caratteri restituito dallo SimpleCrypter è UTF8 e non Latin-1).
Per la lunghezza concordo con g.cassanelli... io allungherei il campo. La lunghezza della stringa di output potrebbe essere superiore a quella di input (anche se non ne sono così sicuro)
Puoi trovare alcune info qui
Controlla se il tuo DB è unicode (il set di caratteri restituito dallo SimpleCrypter è UTF8 e non Latin-1).
Per la lunghezza concordo con g.cassanelli... io allungherei il campo. La lunghezza della stringa di output potrebbe essere superiore a quella di input (anche se non ne sono così sicuro)
Puoi trovare alcune info qui
-

lucabaldini - Pro Gamma

- Posts: 4990
- Joined: 1 October 2010, 17:03
- Location: Bologna
Re: SimpleCrypter
![]() by r.bianco » 16 April 2013, 9:35
by r.bianco » 16 April 2013, 9:35
Grazie ad entrambi
only work and no play makes jack a dull boy
- r.bianco
- Posts: 4979
- Joined: 8 November 2010, 16:46
Re: SimpleCrypter
![]() by r.bianco » 16 April 2013, 12:53
by r.bianco » 16 April 2013, 12:53
Interrogato, l'oracolo risponde: 'WE8MSWIN1252'
Nel progetto InDe, il db non ha il flag 'Campi carattere unicode'
Quindi, per poter utilizzare la SimpleCrypter, devo attivare quel flag? Qual'è il suo effetto sul db? Gli cambia charset? Visto che l'applicazione deve lavorare con più db contemporaneamente ed alcuni di essi non sono modificabili da me, ci sono controindicazioni?
Nel progetto InDe, il db non ha il flag 'Campi carattere unicode'
Quindi, per poter utilizzare la SimpleCrypter, devo attivare quel flag? Qual'è il suo effetto sul db? Gli cambia charset? Visto che l'applicazione deve lavorare con più db contemporaneamente ed alcuni di essi non sono modificabili da me, ci sono controindicazioni?
only work and no play makes jack a dull boy
- r.bianco
- Posts: 4979
- Joined: 8 November 2010, 16:46
Re: SimpleCrypter
![]() by lucabaldini » 16 April 2013, 13:52
by lucabaldini » 16 April 2013, 13:52
WE8MSWIN1252 è Latin-1 che vuol dire i nostri caratteri (ASCII più lettere accentate e poco altro (qui le info)).
Per far sì che Oracle possa memorizzare caratteri al di fuori di quel charset occorre impostarlo a AL32UTF8 (qui ne parlano).
Dopo aver cambiato il tipo di database (operazione che non può essere fatta dentro In.de ma occorre effettuarla su database), devi attivare il flag "Campi carattere unicode" che trovi nella videata delle proprietà del database e ricreare la struttura. Infatti non basta che il database cambi tipo occorre anche che il tipo di dato delle colonne di tipo STRING passi da "varchar2" a "nvarchar2".
A questo punto puoi memorizzare anche caratteri in qualunque lingua, russo e cinese compreso.
Se non puoi farlo (come mi hai detto) ti posso suggerire un'altra soluzione. Potresti memorizzare le password sul database in BASE64. La codifica BASE64 allunga un po' il testo digitato ma la stringa che ottieni è sempre e solo costituita di caratteri ASCII e quindi memorizzabile su qualunque DB.
Ci sono funzioni in C# e Java per convertire da stringa a BASE64 e viceversa. Abbiamo anche una funzione interna (non pubblica) che potrebbe fare al caso tuo. La puoi mappare tu in libreria scrivendo nell'espressione
per la funzione che encoda e
per la funzione che effettua al decode.
Spero di aver risposto alla tua domanda.
Per far sì che Oracle possa memorizzare caratteri al di fuori di quel charset occorre impostarlo a AL32UTF8 (qui ne parlano).
Dopo aver cambiato il tipo di database (operazione che non può essere fatta dentro In.de ma occorre effettuarla su database), devi attivare il flag "Campi carattere unicode" che trovi nella videata delle proprietà del database e ricreare la struttura. Infatti non basta che il database cambi tipo occorre anche che il tipo di dato delle colonne di tipo STRING passi da "varchar2" a "nvarchar2".
A questo punto puoi memorizzare anche caratteri in qualunque lingua, russo e cinese compreso.
Se non puoi farlo (come mi hai detto) ti posso suggerire un'altra soluzione. Potresti memorizzare le password sul database in BASE64. La codifica BASE64 allunga un po' il testo digitato ma la stringa che ottieni è sempre e solo costituita di caratteri ASCII e quindi memorizzabile su qualunque DB.
Ci sono funzioni in C# e Java per convertire da stringa a BASE64 e viceversa. Abbiamo anche una funzione interna (non pubblica) che potrebbe fare al caso tuo. La puoi mappare tu in libreria scrivendo nell'espressione
- Code: Select all
new IDVariant(IDL.Base64Encode($1.stringValue()))
per la funzione che encoda e
- Code: Select all
new IDVariant(IDL.Base64Decode($1.stringValue()))
per la funzione che effettua al decode.
Spero di aver risposto alla tua domanda.
-
lucabaldini - Pro Gamma
- Posts: 4990
- Joined: 1 October 2010, 17:03
- Location: Bologna
Re: SimpleCrypter
![]() by r.bianco » 17 April 2013, 12:11
by r.bianco » 17 April 2013, 12:11
Ottima spiegazione, grazie per la disponibilità.
only work and no play makes jack a dull boy
- r.bianco
- Posts: 4979
- Joined: 8 November 2010, 16:46
7 posts
• Page 1 of 1
Return to Tips & Tricks - Foundation
Who is online
Users browsing this forum: No registered users and 30 guests